
5 Risk Identification Methods for Critical Engineering Environments
16 Sep, 2025
In high-stakes engineering, hidden risks are the real threat, so how do we uncover them in a systematic way? This article offers five clear methods that help you identify risks early and systematically. Implement them within your risk identification processes and identify risks more easily.
When you work in industries like aerospace, space, or medical devices, there’s almost no room for error (if you are not willing to spend a ton of extra resources). Therefore, risk identification isn’t just important; it becomes critical. But here’s the paradox: the more reliable a system becomes, the harder it is to see where the risks are.
In these settings, traditional quality checks aren’t enough. Risk hides in complexity, assumptions, and the unexpected ways systems behave under pressure. To manage this complexity, organizations rely on project documentation and structured logs that make risks traceable from design through operation.
What is Risk Identification?
Risk identification is the process of discovering where and how a system could fail before it actually does. It involves uncovering weaknesses, uncertainties, or design choices that might lead to undesired outcomes under real-world conditions.
In engineering environments, risk identification is the foundation of reliable design. Effective risk identification also depends on maintaining a risk registry where each risk is recorded, tracked, and reviewed.
Typically effective risk identification:
- Starts early, even during concept and design phases
- Continues throughout testing, operations, and maintenance
- Involves both structured methods (analysis tools) and human insight (technician observations)
- Requires deep understanding of the system, its environment, and how it will be used
For risk identification, you need a proactive mindset. Turning uncertainty into something visible, measurable, and manageable.
5 Risk Identification Methods
There are many ways to identify risks in high-reliability systems; here, we discuss five particularly practical and effective. In this article, we explore each of them in detail:
- Mapping system interfaces with an interface matrix
- Validating assumptions through an assumption checklist
- Tracking operational drift using trend analysis
- Identifying failure paths with STPA (Systems-Theoretic Process Analysis)
- Capturing weak signals in an anomaly logbook
While these five approaches are presented as risk identification methods, it is important to note that not all of them are formally categorized this way in the literature. Some are broader analytical tools, and others are techniques developed for reliability, safety, or process improvement. What connects them is that they all help uncover risks that might otherwise remain hidden, making them valuable contributors to the overall process of risk identification.
1. Risk identification by creating an interface matrix
Interface analysis is a standard systems engineering practice. Many failures occur at subsystem boundaries. Formal Interface Control Documents and interface matrices are widely used in space projects and ECSS-driven environments. Using a matrix to review interactions and failure modes is a valid and proven way to uncover risk.
Many critical risks do not sit inside components, they emerge where parts of the system interact.
- Mechanical: Physical connection that transfers force, load, or movement between parts.
- Electrical: Carries electrical power or signal between components.
- Data: Transfers information using analog or digital communication protocols.
- Software (API): Defines how software modules communicate through function calls or services.
- Thermal: Manages heat transfer between components or surfaces.
- Fluid: Enable the flow of liquids or gases between subsystems.
- Human-machine (HMI): Interaction point between users and the system for control or feedback.
Risks in complex systems can appear at the seams where two subsystems meet. These boundaries are often overlooked during testing.
A great way to identify risk here is by building an interface matrix. This is a way to map every point of interaction between subsystems so you can assess each one for possible failure.
How to do it
- List all subsystems across the top and down the side of a grid.
- For each intersecting cell, ask: Does this subsystem exchange data, power, force, or materials with the other?
- Where interfaces exist, write a short description in the cell.
- For each interface:
- Check if there’s a protocol or control document in place.
- Review testing coverage.
- Identify failure modes: What happens if the data is delayed, lost, or corrupted? What if the physical connection degrades?
- Prioritize interfaces with high consequence and low visibility.
This process makes invisible risks visible. It forces you to look at the actual flow between parts, not just the parts themselves.
An example

Common mistakes and what to look out for:
- Overlooking dynamic interactions: Be sure to include timing, synchronization, and environmental dependencies.
- Skipping undocumented interfaces: Temporary test equipment, cables, or software tools often introduce risks.
- Assuming well-tested components are safe: Even certified subsystems can fail when paired with others.
2. Risk identification by validating assumptions through an assumption checklist
Hidden assumptions create blind spots in even the best designs. Many failures in life-critical systems start with something that was considered “obviously true” but never verified.
This is why it’s important to explicitly track and challenge assumptions throughout the project. The process is known by several names – including assumption checklist, assumptions log, assumption matrix, or assumptions register – but the goal is always the same: make assumptions visible, validate them early, and update them as new information emerges.
There are many ways to implement this in practice, but here’s a proven method that works well in complex, high-reliability projects.
How to do it
- Choose a format: Use a simple spreadsheet, logbook, or database with columns for assumption, category, justification, risk if wrong, validation method, owner, and status.
- Assign an assumption recorder during concept or design reviews. This person notes every assumption that’s voiced, especially statements like “we assume…” or “this should work if…”.
- Group assumptions into categories:
- Environmental (e.g. ambient temperature stays below 45°C)
- User behavior (e.g. operator acts within 10 seconds)
- Physics or modeling (e.g. linear material expansion)
- Component reliability (e.g. failure rate <0.01%)
- Timing and synchronization (e.g. sensor response under load)
- For each assumption, document:
- The evidence or reasoning behind it
- The risk if it turns out to be false
- A clear method to validate it (e.g. testing, simulation, historical data)
- Who is responsible for that validation
- When it needs to be validated
- Review the checklist regularly: At each milestone, revisit the list, validate assumptions, add new ones, and update the status of each item.
An example

Common mistakes and what to look out for
- Treating assumptions as facts: If there’s no data behind it, it needs validation.
- Not assigning ownership: Without a clear owner, assumptions are likely to be forgotten.
- Letting the checklist go stale: Assumptions evolve. The list must be reviewed continuously.
- Underestimating impact: Seemingly minor assumptions can lead to major system-level consequences.
- Skipping the validation method: Always define exactly how the assumption will be tested or confirmed.
3. Risk identification by tracking operational drift using trend analysis
Real-world systems rarely behave exactly as designed over time. Small changes in use, environment, or wear can cause parameters to shift gradually. This is known as operational drift, a slow divergence between how a system is supposed to work and how it actually performs.
A proven way to identify this kind of risk is through trend analysis. This method involves tracking critical operational parameters over time to detect subtle, ongoing changes that might not trigger alarms but still signal emerging problems.
This technique is sometimes called condition monitoring, especially in mechanical and aerospace systems. In manufacturing, a similar concept is referred to as process drift. The key idea across all of them is the same: observe how things change gradually, not just when they fail.
How to do it
- Identify key parameters to monitor: Select values that are critical for safety or system integrity. For example, temperature, voltage, pressure, memory usage, power consumption, or vibration levels.
- Collect data across meaningful time periods: Use logs, telemetry, or sensor data from the past few weeks, months, or entire mission phases. More data helps reveal long-term patterns.
- Look for trends, not just outliers: Plot each parameter over time. For example, look for: gradual increases or decreases; narrowing or shifting of margins; increasing variability.
- Compare against design specifications: Check whether parameters are creeping closer to their limits, even if they remain within acceptable thresholds.
- Flag drift patterns for further investigation: Treat long-term movement toward limits as a risk signal. Even if values are still technically “in spec,” the trend may indicate future failure.
- Review trends regularly: Integrate trend reviews into design reviews, post-mission analyses, or routine maintenance checks. Always link findings to potential causes and system changes.
An example
Common mistakes and what to watch for
- Only watching for spikes: Sudden anomalies are easy to spot. Gradual drift is harder.
- Missing the context: Drift may appear only under certain operating modes, times of day, or mission phases.
- Lacking thresholds for action: Without clear boundaries, drift gets ignored until it’s too late.
- Not assigning responsibility: If no one owns the trend analysis, it becomes passive data rather than an active safety tool.
4. Risk identification by identifying failure paths with Systems-Theoretic Process Analysis
Most systems fail not because one part breaks, but because of flawed control. That includes software, automation, and human interaction. To find these failure paths, use STPA (Systems-Theoretic Process Analysis). This method looks at how control actions can lead to unsafe outcomes.
Instead of looking for failures in individual parts, it examines how control actions – or the absence of them – can lead to unsafe situations. By identifying these failure paths, STPA helps engineers define safety constraints and design measures that prevent hazards before they occur. This makes it a powerful tool for integrating system-level risks into your overall risk management process.
How to do it
- Define accidents and hazards first: Start by listing the possible losses, such as mission failure, loss of life, or property damage. Then define hazards, which are system states or conditions that could lead to those accidents. This includes both internal system issues and external environmental conditions.
- Model the control structure: Draw the control structure. Include controllers such as software or human operators, controlled processes, sensors, actuators, and feedback loops. Also include the process model, which describes what the controller believes or perceives about the system’s current state. Add environmental or contextual factors that affect behavior.
- Identify unsafe control actions (UCAs): For each control action in the structure, ask under what conditions it could become unsafe. Use the following four questions to guide your thinking: For each question, specify the context or condition in which the control action would lead to a hazard. These could be operating modes, environmental conditions, or internal system states.
- What happens if the action is not provided when it is needed?
- What happens if it is provided when it should not be?
- What happens if it is provided at the wrong time, too early, too late, or out of sequence?
- What happens if it is applied too long or stopped too soon?
- Analyze causal scenarios and control flaws: Once you identify a UCA, explore what could cause it. Consider:
- Incorrect or incomplete process models.
- Missing, delayed, or inaccurate sensor feedback.
- Timing problems.
- Human operators making mistakes.
- Software bugs or errors.
- Mechanical failure to controls
- Derive safety constraints and plan mitigation: Translate each UCA into a safety constraint. These are requirements that must be met to keep the system in a safe state. Then define how you will test or enforce these constraints through simulation, design changes, or operating procedures.
An example
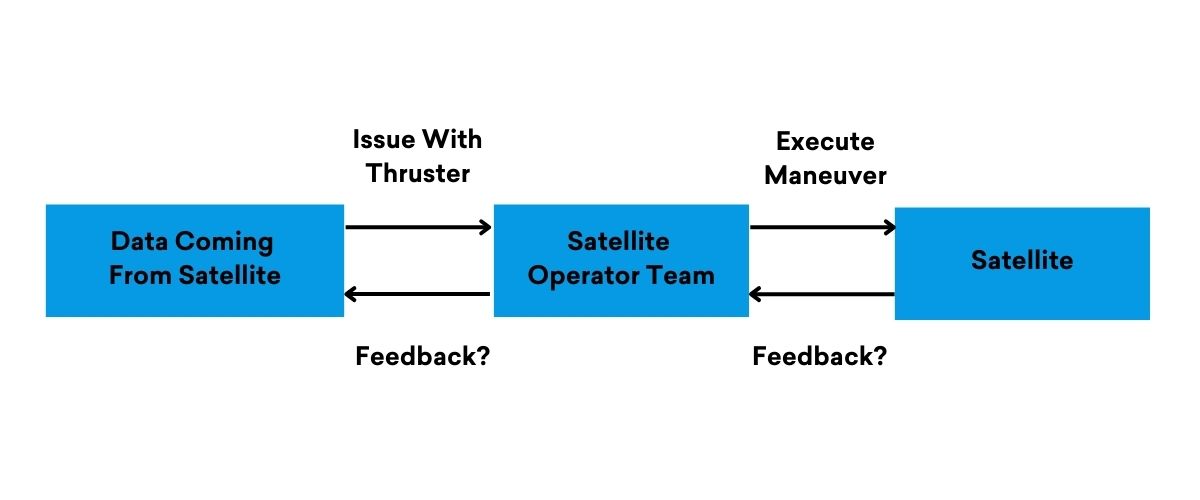
Common mistakes to watch out for
- Forgetting to define hazards before identifying unsafe control actions. Without hazards, you do not know what makes an action unsafe.
- Leaving out the context that makes a control action dangerous. Control actions are not unsafe in isolation.
- Assuming the controller always has correct and up-to-date information. Process models can be wrong or incomplete.
- Ignoring feedback delays or assuming sensors are perfect.
- Identifying UCAs without translating them into actionable design requirements or testable constraints.
5. Risk identification by capturing weak signals in an anomaly logbook
Small anomalies can precede bigger failures. Engineers and operators frequently notice things like unusual noises, small delays, flickers of behavior long before full system failures. These can be weak signals. Capturing them systematically helps you identify risk that isn’t obvious in normal monitoring or compliance checks.
Here is a method you can use:
How to do it
- Create a shared anomaly logbook: Use a digital or physical format that is easy to access during testing, operation, maintenance. Make it part of daily or weekly routines.
- Train people to log weak signals/anomalies: Instruct engineers, operators, technicians to note anything unusual – even if it seems small. Examples:
- “Valve A clicked louder than usual”
- “UI lagged when battery hit 20%”
- “Sensor reset after reboot”
- Include context for each entry: For example, mention the subsystem it is part of, the observed anomaly, context, concern, owner and status.
- Review regularly: At least weekly or after each test phase or mission segment:
- Group similar entries
- Look for patterns, recurring anomalies
- Feed findings into risk review meetings or design reviews
- Promote culture and follow-up: Recognize contributions even when no major fault is found. Ensure someone is responsible for reviewing, tracking, and following up on anomalies.
An example
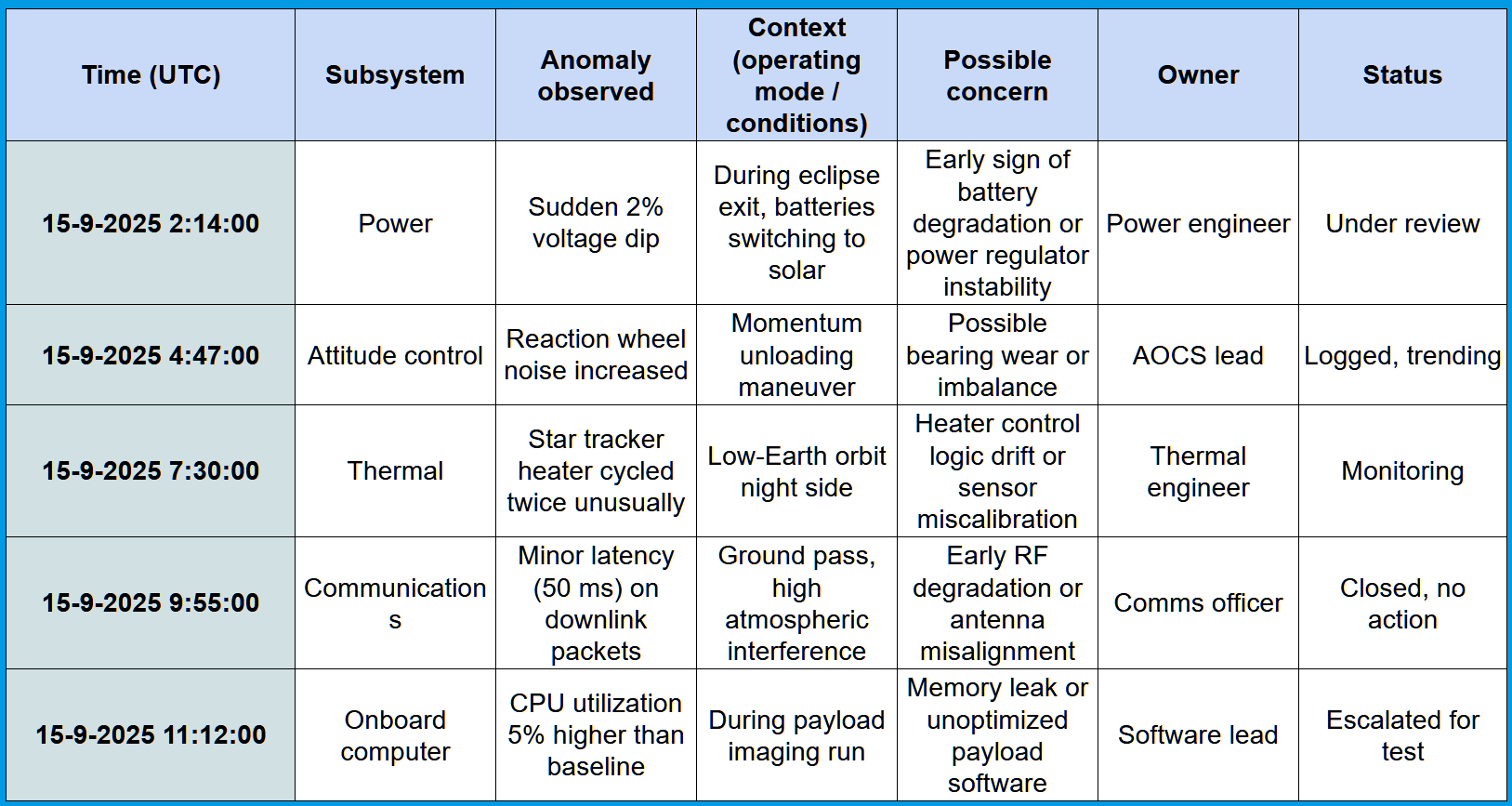
Common mistakes and what to look out for
- Not clearly owning the logbook: Something gets logged, but no one monitors or acts on it.
- Dismissing small anomalies: If every deviation is ignored because “it doesn’t matter”, you will miss early warnings.
- No follow-up or feedback: If anomalies are never discussed or addressed, people stop reporting them.
- Lack of structure: Entries without context (time, mode, conditions) make it hard to spot real patterns.
Integrating proper risk management requires a whole toolset
No single technique is sufficient to reveal all risks in complex, high-reliability systems. What matters is integration. An interface matrix makes hidden connections visible. An assumption checklist challenges untested beliefs. Trend reviews highlight a gradual drift. STPA uncovers unsafe control paths. Anomaly logbooks capture weak signals from the front line.
To make these findings actionable, they should be documented clearly in project documentation and converted into an action list that assigns responsibility and deadlines. From there, critical risks belong in a risk registry, where they can be tracked, prioritized, and reviewed. Finally, each identified risk should lead to a concrete risk mitigation plan, ensuring that insights do not stop at identification but translate into safer and more reliable systems.
References
- Challenges of big-science: A matrix-based interface model to manage technical integration risks in multi-organizational engineering projects
- Assumption-based risk management (ABRM)
- Predicting and preventing process drift
- STPA handbook
- The use of weak signals in occupational safety and health: An empirical study

Desmond Gardeslen
Product Marketing Manager
Passionate about the intersection of space technology, marketing, business, engineering, and innovation.


